Importing Data¶
LOAD CSV¶
LOAD CSV can handle local and remote files, and there is some syntax
associated with each. This can be an easy thing to miss and end up with an access
error, so we will try to clarify the rules here.
Local files are referenced with a
file:///prefix before the file name.Web-hosted files can be referenced directly with their URL, like
https://host/path/data.csv.
In this example, we’re given three CSV files:
Import Folder¶
In Neo4j desktop, the csv files you want to upload should be located in the import folder associated with the database:
Step by Step¶
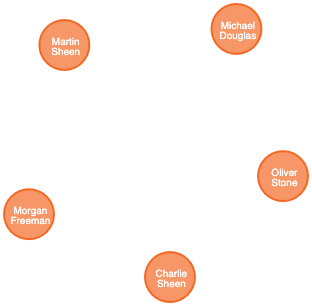
Using the following Cypher queries, we’ll create a node for each person, a node for each movie and a relationship between the two with a property denoting the role. We’re also keeping track of the country in which each movie was made.
Let’s start with importing the persons. The CSV file we’re using looks like this:
LOAD CSV WITH HEADERS FROM "file:///persons.csv" AS csvLine
CREATE (p:Person {id: toInteger(csvLine.id), name: csvLine.name})
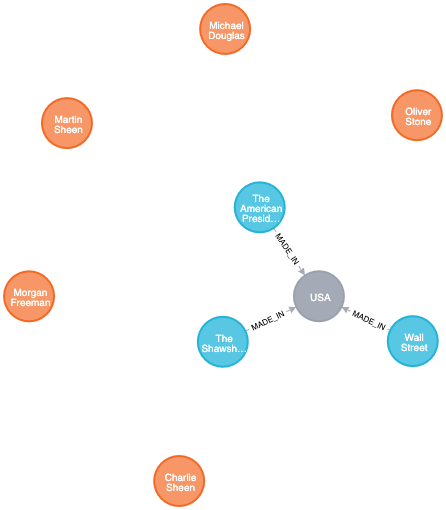
Now, let’s import the movies. This time, we’re also creating a relationship to the country in which the movie was made.
If you are storing your data in a SQL database, this is the one-to-many relationship type.
We’re using MERGE to create nodes that represent countries.
Using MERGE avoids creating duplicate country nodes in the case where multiple movies have been made in the same country.
When using MERGE or MATCH with LOAD CSV we need to make
sure we have an index or a unique constraint on the property we’re merging.
This will ensure the query executes in a performant way.Before running our query to connect movies and countries we’ll create an index for the name property on the Country label to ensure the query runs as fast as it can:
CREATE INDEX mycountryindex
FOR (n:Country)
ON (n.name)
LOAD CSV WITH HEADERS FROM "file:///movies.csv" AS csvLine
MERGE (country:Country {name: csvLine.country})
CREATE (movie:Movie {id: toInteger(csvLine.id), title: csvLine.title, year:toInteger(csvLine.year)})
CREATE (movie)-[:MADE_IN]->(country)
MATCH (a:Person),(b:Country),(c:Movie)
RETURN a,b,c
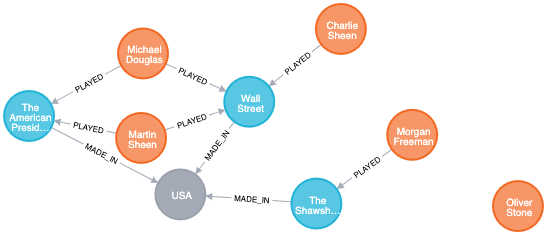
Lastly, we create the relationships between the persons and the movies. Since the relationship is a many to many relationship, one actor can participate in many movies, and one movie has many actors in it. We have this data in a separate file.
We’ll index the id property on Person and Movie nodes.
The id property is a temporary property used to look up the
appropriate nodes for a relationship when importing the
third file. By indexing the id property, node lookup
(e.g. by MATCH) will be much faster.
Since we expect the ids to be unique in each set,
we’ll create a unique constraint.
This protects us from invalid data since constraint creation will fail if there are multiple nodes with the same id property.
Creating a unique constraint also creates a unique index (which is faster than a regular index).
CREATE CONSTRAINT ON (person:Person) ASSERT person.id IS UNIQUE
CREATE CONSTRAINT ON (movie:Movie) ASSERT movie.id IS UNIQUE
Now importing the relationships is a matter of finding the nodes and then creating relationships between them.
LOAD CSV WITH HEADERS FROM "file:///roles.csv" AS csvLine
MATCH (person:Person { id: toInteger(csvLine.personId)}),(movie:Movie { id: toInteger(csvLine.movieId)})
CREATE (person)-[:PLAYED { role: csvLine.role }]->(movie)
Finally, as the id property was only necessary to import the relationships, we can drop the constraints and the id property from all Movie and Person nodes.
DROP CONSTRAINT ON (person:Person) ASSERT person.id IS UNIQUE
DROP CONSTRAINT ON (movie:Movie) ASSERT movie.id IS UNIQUE
MATCH (n) WHERE n:Person OR n:Movie REMOVE n.id
LOAD CSV (from Web)¶
It is perfectly possible to load data from an csv-file located on the web (for example a public repository).
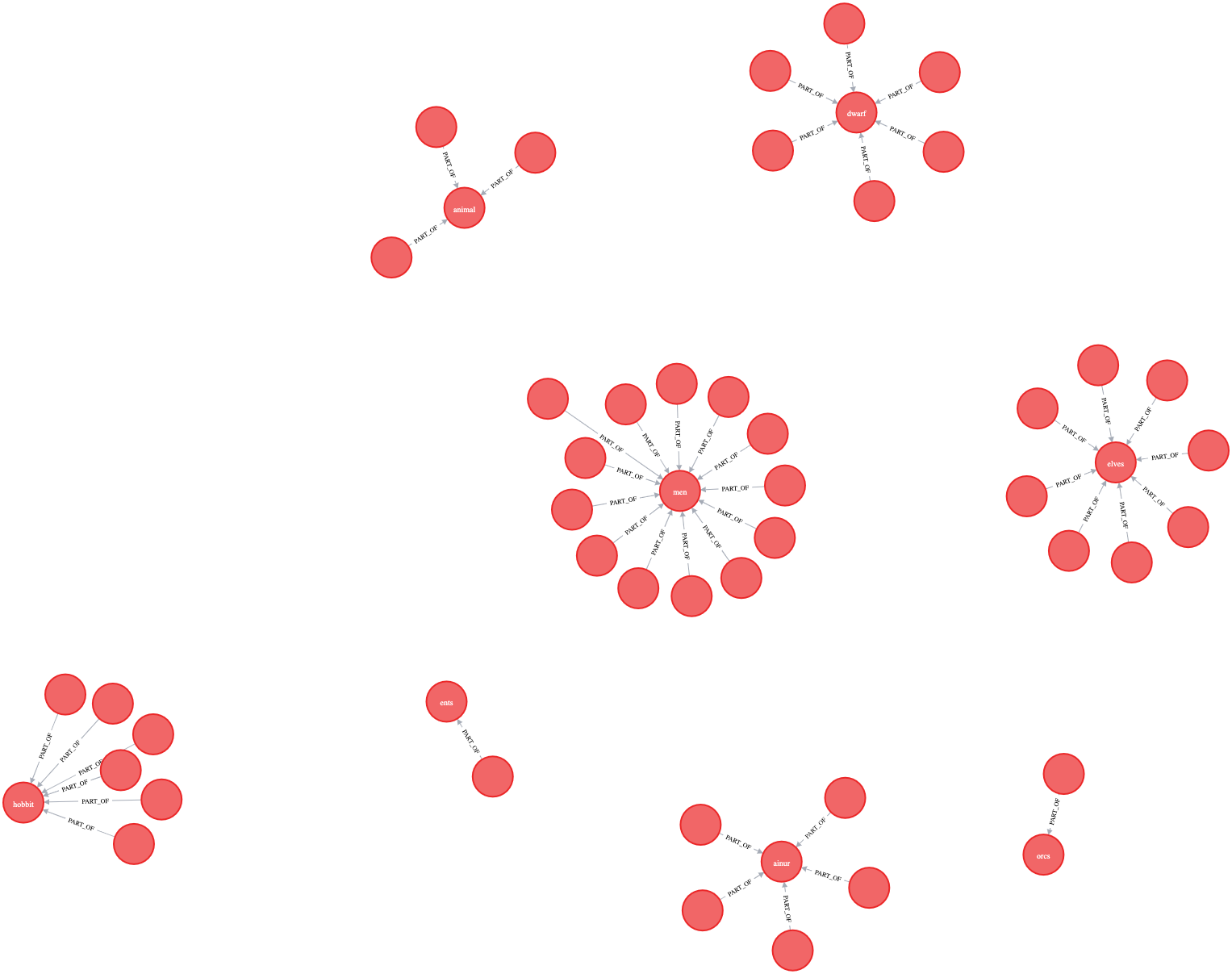
A good example is a data-set describing the characters in Lord of the Rings.
The nodes are stored into a csv file (https://raw.githubusercontent.com/morethanbooks/projects/master/LotR/ontologies/ontology.csv)
The code below makes use of stored procedures: APOC = Awesome Procedures On Cypher.
LOAD CSV WITH HEADERS FROM "https://raw.githubusercontent.com/morethanbooks/projects/master/LotR/ontologies/ontology.csv" as row
FIELDTERMINATOR "\t"
WITH row, CASE row.type WHEN 'per' THEN 'Person'
WHEN 'gro' THEN 'Group'
WHEN 'thin' THEN 'Thing'
WHEN 'pla' THEN 'Place' END as label
CALL apoc.create.nodes(['Node',label],
[apoc.map.clean(row,['type','subtype'],[null,""])])
YIELD node
WITH node, row.subtype as class
MERGE (c:Class{id:class})
MERGE (node)-[:PART_OF]->(c)
The nodes are created and are given 4 different labels based on the column type:
Person
Group
Thing
Place
These nodes are then assigned to a Class using the PART_OF relationship. We can view the result :
MATCH (n:Person)-[]-(c:Class)
RETURN n,c
Procedures used:
Last change: Oct 30, 2023