Graph Catalog¶
The graph catalog is a concept within the GDS library that allows managing multiple graph projections by name. Using its name, a created graph can be used many times in the analytical workflow. The graph catalog exists as long as the Neo4j instance is running. When Neo4j is restarted, graphs stored in the catalog are lost and need to be re-created.

STORED GRAPH -> PROJECTION -> CATALOG¶
A projected graph can be stored in the catalog under a user-defined name. Using that name, the graph can be referred to by any algorithm in the library.
The projected graphs will reside in the catalog until:
the graph is dropped using
gds.graph.dropthe Neo4j database from which to graph was projected is stopped or dropped
Why ?¶
Imagine you are working with a massive graph stored in Neo4j and are seeking to apply a particular graph algorithm. Think about the large movie database which is used in many Neo4j examples. If you are only interested in nodes carrying the label DIRECTOR, then a named graph will come to the rescue, because it will allow you to carve out all those nodes and created a new graph.
With the graph.create-function, one can
extract from the original data-set a much smaller dataset. This new (virtual) set
comes with many advantages:
it requires less memory
nodes and relationships can be deleted, edited,added, … WITHOUT doing any harm to the original data.
Graph catalog function¶
Neo4j provides the following set of functions to work with a graph catalog:
gds.graph.create:Creates a graph in the catalog using aNativeprojection.gds.graph.create.cypher: Creates a graph in the catalog using aCypherprojection.gds.graph.list: Prints information about graphs that are currently stored in the catalog.
CALL gds.graph.list()
YIELD
graphName
gds.graph.exists: Checks if a named graph is stored in the catalog.gds.graph.removeNodeProperties: Removes node properties from a named graph.gds.graph.deleteRelationships: Deletes relationships of a given relationship type from a named graph.gds.graph.drop: Drops a named graph from the catalog.gds.graph.writeNodeProperties: Writes node properties stored in a named graph to Neo4j.gds.graph.writeRelationship: Writes relationships stored in a named graph to Neo4j.
Creating graphs in the catalog¶
A projected graph can be stored in the catalog under a user-defined name.
There are two variants of projecting a graph from the Neo4j database into main memory:
Native projection
Cypher projection
Native projection¶
This projection (our favourite one in this course) creates a graph in the catalog using 3 parameters:
graphName
nodeProjection
A list of nodes (as a string) from the original dataset that needs to be incorporated in the the graph.
relationshipProjection
A list of relationships (or one single relationship) that should be part of the to-be-created graph.
Cypher projection¶
This projection using Cypher in the projection of the named graph. Three different parameters are required :
graphName
nodeQuery A Cypher query is used to select those nodes that should be part of the graph.
relationshipQuery
A Cypher query to specify the relationship between the selected nodes.
In both the native and Cypher projection, an optional configuration parameter is also possible but not in scope for this course.
Note
Native or Cyper ?

With both projections one can achieve a similar result. Native projections have two advantages:
They focus on performance
It is possible to change the relationship’s direction in the projected graph. Relationship directions can be reversed.
Example¶
Using native projection we will construct a couple of graphs. To achieve this we start with the construction of simple stored graph :
CREATE
(nadia:Person { name: 'Nadia', age: 26 }),
(dan:Author { name: 'Dan Brown', age: 60 }),
(jan:Person { name: 'Jan', age: 38 }),
(charlotte:Person { name: 'Charlotte', age: 20, ratings: [5.0] }),
(davinci:Book { name: 'Da Vinci Code', isbn: 1234, numberOfPages: 310, ratings: [1.0, 2.0, 3.0, 4.5] }),
(angels:Book { name: 'Angels & Demons', isbn: 4242, price: 19.99 }),
(nadia)-[:KNOWS { since: 2010 }]->(jan),
(nadia)-[:KNOWS { since: 2018 }]->(charlotte),
(nadia)-[:READ { numberOfPages: 4 }]->(davinci),
(nadia)-[:READ { numberOfPages: 42 }]->(davinci),
(jan)-[:READ { numberOfPages: 30 }]->(davinci),
(charlotte)-[:READ]->(angels),
(dan)-[:WROTE]->(angels),
(dan)-[:WROTE]->(davinci)
This results in :
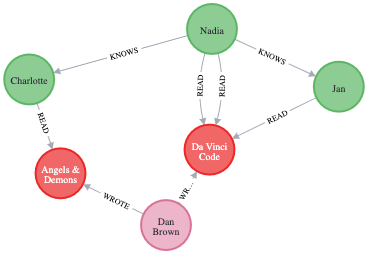
Suppose we are only interested in the Persons connected through
the relationship KNOWS. We can achieve this projection into a graph
carrying the name friends:
CALL gds.graph.create(
'friends',
'Person',
'KNOWS')
YIELD
graphName AS graph,
nodeProjection,
nodeCount AS nodes,
relationshipProjection,
relationshipCount AS rels
Similarly one can create the same graph, but removing the direction from the KNOWS relationship:
CALL gds.graph.create(
'friends_undirected',
'Person',
{KNOWS: {orientation: 'UNDIRECTED'}})
YIELD
graphName AS graph,
nodeProjection,
nodeCount AS nodes,
relationshipProjection,
relationshipCount AS rels
We can also add Author-label and the WROTE relationship :
CALL gds.graph.create(
'friends_undirected_author',
['Person','Author'],
['WROTE',{KNOWS: {orientation: 'UNDIRECTED'}}])
YIELD
graphName AS graph,
nodeProjection,
nodeCount AS nodes,
relationshipProjection,
relationshipCount AS rels
When projecting a graph, it is good practice to export those properties of both nodes and relationships that might be used in a later phase when applying algorithms to the name graph. We can add for example the age of the Person and Author label
CALL gds.graph.create(
'friends_undirected_author_with_properties',
{ Person:{properties: 'age'},
Author:{properties: 'age'}
},
['WROTE',{KNOWS: {orientation: 'UNDIRECTED'}}])
YIELD
graphName AS graph,
nodeProjection,
nodeCount AS nodes,
relationshipProjection,
relationshipCount AS rels
In the projected graph, one can add do CRUDE-operations on nodes and properties. Graphs can then be used as inputs into different Algorithms. It is also possible to export the graph as a new database. For example, when exporting the graph ‘’friends’‘:
CALL gds.graph.export('friends', { dbName: 'myowndatabase' })
After this step you need to manually create the database using the command :
:use system
CREATE DATABASE myowndatabase;
When using this database (:use myowndatabase ) the resulting graphs looks different
from the graph we created at the very beginning of this exercise :
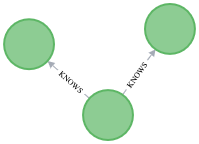
We did not project important node properties such as name and age. Hence
this exported graph is very basic.
Listing graphs in the catalog¶
Once we have created graphs in the catalog, we can list information about either all of them or a single graph using its name.
The syntax for creating a graph :
CALL gds.graph.list('whole-graph')
YIELD graphName, nodeProjection, relationshipProjection, nodeQuery,
relationshipQuery,nodeCount, relationshipCount, schema,
degreeDistribution, creationTime, modificationTime,
sizeInBytes, memoryUsage;
Estmating memory¶
The graph algorithms library operates completely on the heap, which means we’ll need to configure our Neo4j Server with a much larger heap size than we would for transactional workloads.
A model has three ingredients, each having their data requirements.
Node ids
Relationships - pairs of node ids. Relationships are stored twice if orientation:
UNDIRECTEDis used.Weights
If the estimation check can determine that the current amount of free memory is insufficient to carry through the operation, the operation will be aborted and an error will be reported.
Imagine we want to run the wcc algorithm using the stream execution model.
To estimate the required memory on a graph name whole-graph:
CALL gds.wcc.stream.estimate('whole-graph') YIELD
requiredMemory, nodeCount,relationshipCount
It is also possible to estmate the required memory for just the graph itself, or to have an estimation of a new to be created graph
Example:
Imagine you have to create a network for 5000 shares with an undirected correlation matrix of 5000 x (5000-1)/2 relationships (=12,497,500).
How much memory is required in this case ?
CALL gds.graph.create.estimate('*', '*', {
nodeCount: 5000,
relationshipCount: 1249750000,
nodeProperties: ['name','country','sector'],
relationshipProperties:[ 'correlation']
})
YIELD requiredMemory
Which has as output : 10728 MiB
Note
Solving lack of memory
The amount of free memory can be increased by either dropping unused graphs from the catalog, or by increasing the maximum heap size prior to starting the Neo4j instance.
Last change: Oct 30, 2023